|
Il fattore X: l’eXtensible Markup Language

|
All’inizio degli anni Novanta del XX secolo, ben poche persone avrebbero scommesso sull’enorme successo che avrebbe avuto di lì a poco il World Wide Web, l’invenzione di Tim Berners-Lee basata principalmente su due tecnologie complementari: il protocollo di trasmissione http (Hypertext Transfer Protocol) e HTML, il linguaggio utilizzato per la creazione dei documenti ipertestuali derivato da SGML. |
L’evoluzione rapidissima della rete internet, fomentata dalla stessa semplicità dell’HTML, aveva però quasi immediatamente evidenziato i limiti semantici intrinseci al linguaggio che struttura le pagine del Web, costringendo i suoi stessi progettatori a tornare indietro e rivalutare l’ipotesi di utilizzare il misterioso Standard Generalized Markup Language.
Così, nel 1995, si faceva strada tra gli esponenti del W3C ![]() , il consorzio per la gestione del Web, l’idea di portare SGML su internet, mantenendone le potenzialità ma rendendolo al tempo stesso più semplice e manipolabile.
, il consorzio per la gestione del Web, l’idea di portare SGML su internet, mantenendone le potenzialità ma rendendolo al tempo stesso più semplice e manipolabile.
L’anno successivo si costituiva pertanto un Working Group finalizzato a definire le specifiche di un nuovo subset: l’equipe, composta da undici membri e coordinata da James Clark, dopo un intenso lavoro di circa venti settimane, tra luglio e novembre del 1996 pubblicava la prima Working Draft con l’ormai famosa presentazione di John Bosak alla SGML ’96 Conference.
A partire dal 1998, la SGML Conference diventa ufficialmente XML Conference
All’interno delle specifiche del W3C Alla WD segue la Candidate Recommendation (CR) e infine la W3C Recommendation (REC), che definisce lo standard in maniera ufficiale.
Nel caso di XML la CR è stata pubblicata nel dicembre 2007 (http://www.w3.org/TR/PR-xml-971208) e la prima REC nel febbraio 1998 (http://www.w3.org/TR/1998/REC-xml-19980210).
La REC più recente è quella relativa alla quarta edizione, dell’agosto 2006 |
Era nato l’eXtensible Markup Language, un metalinguaggio dalla sintassi semplificata, in grado di definire numerosi linguaggi associati per i link, i nomi dei tag, i fogli di stile e la descrizione di metainformazioni.
|
XML History |
Le differenze tra XML e il suo pesante genitore si rendevano evidenti sin dalla pubblicazione delle sue specifiche: quelle di XML sono di circa 25 pagine contro le 150 di SGML, e in poco meno di due settimane uno studente universitario riusciva a scrivere un parser, un programma che in grado di verificarne la correttezza sintattica1. Ma alla fine degli anni ’90, anche dopo la pubblicazione della prima Recommendation, XML appariva ancora abbastanza acerbo, nonostante le sue potenzialità – e soprattutto il fatto di essere impiegabile nel campo della portabilità dei dati, dei formati non proprietari e della condivisione tra applicazioni diverse – fossero sotto gli occhi di tutti. |
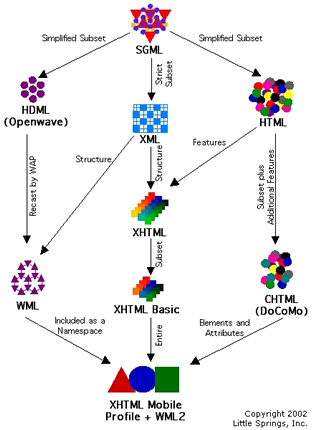
Anche il progetto originario di sostituire HTML nei browser, aggiungendo così nuove funzionalità alle pagine web, finiva col cozzare con lo scarso supporto da parte dei browser stessi, facendo deviare XML verso altre modalità di impiego.
Quello che mancava era una killer application che dimostrasse le reali possibilità di questo standard.
Nonostante XML fosse nato con l’obiettivo di superare l’HTML, appariva infatti chiaro come i presupposti teorici che lo avevano formato – di natura dichiarativa piuttosto che procedurale – ne impedissero un effettivo impiego nella creazione di file da immettere in internet.
Pur derivando entrambi da SGML, le differenze tra HTML e XML sono profonde. HTML è infatti un linguaggio procedurale, pensato per la formattazione dei documenti; viceversa XML è finalizzato alla strutturazione delle informazioni. Oggi tuttavia sarebbe possibile tradurre tutto l’HTML in XML, producendo file XHTML.
Le specifiche di XHTML sono state rilasciate dal W3C Recentemente infatti, si fa largo l’idea di riprogettare, utilizzando proprio la sintassi dell’XHTML l’intera struttura di internet, sviluppando l’idea di un Web Semantico che sia in grado di superare gli attuali limiti e consentire un recupero dell’informazione maggiormente pertinente agli interessi umani: la gestione e il recupero di dati da documenti non più costruiti da una semplice sequenza di testo, ma organizzati nelle strutture gerarchiche proprie di XML, apre infatti inedite possibilità di progettazione. |
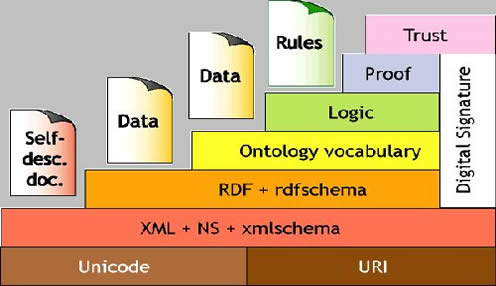
Lo schema del Semantic Web
Ma, grazie alla combinazione delle sue caratteristiche, del supporto da parte del W3C ![]() e del relativo lavoro sulle specifiche disponibili, insieme alla disponibilità di numerosi programmi open source, il successo di XML era solamente rimandato, anche se ancora con la necessità di trovare il modo.
e del relativo lavoro sulle specifiche disponibili, insieme alla disponibilità di numerosi programmi open source, il successo di XML era solamente rimandato, anche se ancora con la necessità di trovare il modo.
Il modo è stato, dal 2000 in poi, l’ingresso di XML in internet attraverso la finestra – piuttosto che la porta – ossia, non come veicolo dei contenuti principali ma delle loro (meta)informazioni aggiuntive, sfruttando la possibilità insita nel linguaggio di separare nettamente la struttura dei dati immessi su computer dalla visualizzazione finale degli stessi.
Diversamente dall’HTML infatti, in un documento XML non è necessario fare alcun riferimento al modo in cui le informazioni verranno visualizzate: le regole per la visualizzazione saranno infatti inserite in un file esterno, chiamato foglio di stile.
Le caratteristiche di quello che il W3C ![]() definisce «a common syntax for expressive structure in data» sono inoltre molto semplici e permettono di definire la struttura che descrive il contenuto informativo all’interno dello stesso documento che lo produce, precisandone l’articolazione attraverso l’immissione di marcatori.
definisce «a common syntax for expressive structure in data» sono inoltre molto semplici e permettono di definire la struttura che descrive il contenuto informativo all’interno dello stesso documento che lo produce, precisandone l’articolazione attraverso l’immissione di marcatori.
L’eXtensible Markup Language consente infatti di costruire diversi linguaggi di codifica, ciascuno per una particolare tipologia di documenti, ma sopratutto non fornisce alcuna prescrizione riguardo alla forma, la quantità e il nome dei tag da utilizzare, ma solo una sintassi generica per la loro definizione e il loro utilizzo nell’identificazione degli elementi di testo.
Un file XML è in realtà un semplice documento di testo, le cui sezioni sono racchiuse all’interno di coppie di marcatori (tag), distinte dal testo libero (PcData, Parsable Character Data) per il fatto di essere racchiuse tra parentesi uncinate. |
 |
Caratteristica di XML è quella di essere case sensitive, ovvero di fare differenza tra lettere maiuscole e minuscole: pertanto, un tag <PERSONA> sarà diverso da un tag <Persona> o <persona>. |
Affinchè il documento sia ben formato (well formed), le specifiche prevedono l’immissione nel testo di:
|
|
All’interno della Document Instance si possono immettere gli elementi, inseriti all’interno di parentesi uncinate (<ELEMENTO>).
es. <PERSONA> |
XML non fornisce alcun sistema per identificare il significato di un elemento o cosa debba codificare: un elemento può infatti contenere solo testo, oppure altri elementi, creando una struttura ad albero come quella evidenziata nell’esempio sottostante, in cui gli elementi di un’edizione diplomatica sono instanziati gli uni dentro gli altri.
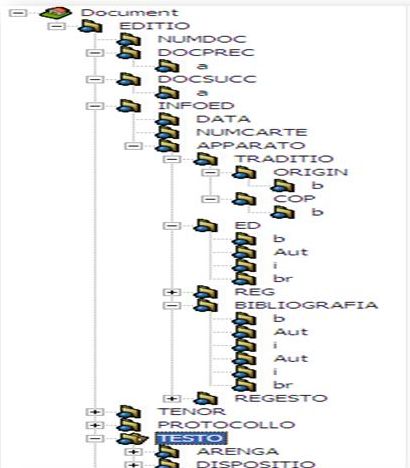
Parte della struttura ad albero della marcatura realizzata sul codice Vat.Lat.3880
Un documento XML è pertanto una sequenza organizzata di elementi, racchiusi all’interno di un elemento-padre, da cui discendono numerosi elementi-figli.
A sua volta un elemento può contenere attributi, ovvero informazioni di secondo livello relative alle proprietà degli elementi, posizionate all’interno del tag di apertura di un elemento ed espresse nella forma nome_attributo=“valore”; ad un elemento posso essere associati molteplici attributi, separati da uno spazio,
|
es. <PERSONA ente=“Università degli Studi di Palermo” e-mail=“serenafalletta@libero.it” >Serena Falletta</PERSONA> |
Tramite un attributo può dunque essere descritto lo status particolare di un elemento, o fornire maggiori informazioni sull’elemento cui si affiancano, in funzione descrittiva.
XML prevede anche la possibilità di immettere commenti racchiusi tra stringhe all’interno del testo (<!-- Questo è un commento -->) inseribili ovunque, ma ignorati dal parser, un modulo software deputato a rilevare la correttezza del documento analizzato in conformità alle regole generali della sintassi XML (ad esempio, i tag aperti devono essere sempre chiusi) e alle specifiche fornite dal compilatore nella Document Type Definition, qualora fosse presente.
I commenti sono quindi invisibili al processore XML e servono solo per utenti umani. |
Il linguaggio permette anche di comunicare al parser che non si vuole analizzare una porzione di testo marcata, o che a quella sezione va riservato un trattamento particolare, attraverso il comando <![CDATA[ ..... ]]>: all’interno di questo segmento ogni stringa di carattere verrà quindi considerata dal programma come semplice sequenza alfanumerica.
La sintassi delineata lascia facilmente comprendere come l’eXtensible Markup Language – pur essendo in grado di produrre un testo perfettamente impaginato – punti, da buon linguaggio dichiarativo, alla descrizione della struttura astratta di un documento piuttosto che il suo aspetto grafico.
Ciò che più conta è il fatto che, configurandosi paradossalmente come un linguaggio vuoto, riempito solo dalle regole che ne permettono la stessa progettazione, XML sia in grado di focalizzare la codifica sulla semantica del testo e sulla relazione tra i dati in esso contenuti, di cui tratteggia un ordinamento gerarchico capace di sovrintendere, anche graficamente, l’organizzazione degli elementi all’interno del file.
Da ciò discende, conseguentemente, un grande vantaggio: XML permette infatti la rappresentazione dell’informazione in modo indipendente sia dal linguaggio di programmazione con cui è stata sviluppata, sia dal sistema operativo su cui è in esecuzione.
In altre parole, XML è platform indipendence e in quanto tale, è il linguaggio ideale per l’interoperabilità, la portabilità e lo scambio di dati tra software diversi, superando i classici problemi connessi alla codifica digitale dei documenti, finora legata alla disponibilità dei dispositivi tecnologici.
 |
Per questi motivi, l’eXtensible Markup Language è oggi utilizzato in ambiti estremamente diversi, grazie alla sua natura ibrida, a cavallo tra il modello di rappresentazione dei dati e lo standard per la definizione di documenti, che ha contribuito ad assicurargli il ruolo di anello di congiunzione tra il Web, formato da documenti non strutturati e le basi di dati, contenenti informazioni strutturate. |
La sua estrema flessibilità e la possibilità di una leggibilità non mediata dalla macchina consentono infatti di impiegarlo sia nella costruzione di basi di dati testuali che per produrre documenti di vario genere – ipertestuali, .rtf, .doc, .pdf – con i vantaggi che l’uniformazione su un unico standard comporta. |
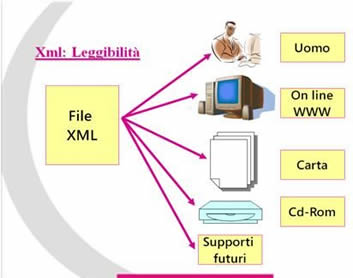 |
In sintesi XML è: |
|
|
|
|
|
|
Effettuare una panoramica globale dei correnti usi di XML è estremamente arduo e non interessa in questa sede se non nella misura in cui risulti utile individuare i settori che potrebbero interessare la ricerca storica, dove le ricadute pratiche del suo utilizzo appaiono immediate.
In ambito scientifico linguaggi creati utilizzando XML sono chiamati applicazioni o vocabolari.
Tra i più famosi: MathXML (Mathematical Markup Language), CML (Chemical Markup Language), OSD (Open Software Description). Per le applicazioni di XML si rimanda pertanto ad un interessante sito, Monastic XML: an ascetic view of XML best practices
Monastic XML si propone come una risorsa informativa sugli utilizzi più appropriati di XML, mettendo in guardia contro impieghi che potrebbero rivelarsi controproducenti nel medio e lungo termine. In Italia, il settore che maggiormente ha abbracciato questa tecnologia è quello archivistico, da sempre interessato al recupero di dati esistenti su formato diverso.
Tra gli esempi di implementazioni XML vanno citati: XSTAR (System for Textual and Archeological Research) Realizzazioni tecniche sono invece la Guida Generale degli Archivi di Stato Italiani
XML viene inoltre usato come formato di esportazione dei dati o come formato di dati forniti in risposta alle query impostate dall’utente in software di descrizione archivistica come Sesamo, Arianna, Guarini archivi e sistemi informativi nazionali e territoriali (SIAS, SIUSA, PLAIN), cfr. S. Auricchio, I. Barbanti, S. Mazzini, C. Veninata, XML per l’informatizzazione degli archivi storici comunali, in Dalla Fonte alla Rete. Il linguaggio XML e la codifica dei documenti storici, archeologici e archivistici, a cura di F. Nicolucci; numero monografico di Bollettino di Informazioni Centro Ricerche Informatiche per i Beni Culturali, 12 (2002) 1, pp. 95-112. |
La possibilità di progettare e nominare di volta in volta gli elementi da codificare, e quella – ancor più preziosa – di stratificazione e aumento indefinito dei tag, rendono infatti questo sistema particolarmente adatto alla digitalizzazione delle fonti storiche senza che, modificando le ipotesi iniziali del proprio studio, uno studioso debba necessariamente riprogrammare di volta in volta tutto il lavoro, con il vantaggio – straordinario – di rendere disponibile il testo integrale delle fonti anziché una sua rielaborazione in un record di database.
L’annidiamento all’interno del documento dei marcatori, garantendo la formalizzazione e la gerarchizzazione delle informazioni ritenute significative attraverso uno schema di regolarizzazione di nomi e cose notevoli, che rende perfettamente la varietà dei fenomeni semantici presenti all’interno di un documento, permette infatti di mantenere la complessità informativa sulla struttura, le partizioni e le funzioni delle singole porzioni di testo, che però restano saldamente ancorate al contesto di appartenenza.
Se nell’allestimento di una tradizionale edizione interpretativa è sempre problematico dar conto con chiarezza e concisione delle numerose costruzioni testuali che compongono il testo, è evidente che la possibilità di una codifica nascosta, ma operante a richiesta, mette in grado di restituire i diversi livelli di redazione e composizione di un’opera, rendendo agevole la percezione di ciò che di volta in volta l’editore o il lettore ritengono significativo.
Contemporaneamente XML,è in grado di recuperare i metadati inseriti sotto forma di attributi, che possono comunque essere nascosti nell’output, risultando fondamentale anche ai fini della selezione e ordinamento dinamico dei contenuti, la costruzione automatica di indici, liste, concordanze, repertori, e producendo ritorni significativi in termini di information retrieval all’interno di corpus documentari e testuali.
Fermo restando che l’apporto più interessante dell’utilizzo di XML resta la possibilità di mantenere l’integrità del testo, senza che esso subisca la rilevante perdita di informazioni propria dell’immissione dei dati all’interno di un database, è comunque proficuo riassumere gli ulteriori vantaggi prospettati dall’immissione di questa marcatura nella codifica digitale di fonti storiche:
|
|
|
|
|
|
|
|
Nell’ambito del progetto presentato in questa sede, XML è apparso dunque il contenitore ideale di informazioni e metadati perché, oltre alla sua natura standardizzata e all’ampia diffusione in progetti editoriali di stampo simile, consente di raccogliere e definire la struttura sematica completa del codice Vat.Lat.3880, lasciando spazio a future specializzazioni e raffinamenti nella marcatura.
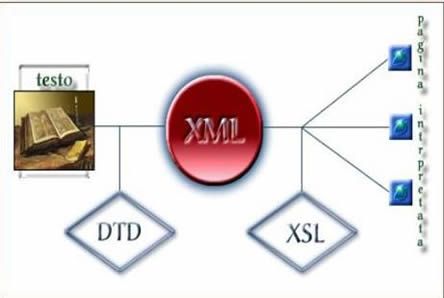
Un’applicazione XML: dal testo manoscritto, attraverso la codifica, alla pagina web
In tale prospettiva l’eXtensible Markup Language ha rappresentato anzi, non solo un versatile intermediario che ha consentito la comprensione e l’approccio ai differenti progetti editoriali esaminati nella fase iniziale di questo studio, ma anche il passaggio e il superamento dei diversi stadi redazionali del lavoro proposto, la cui storia stessa ha comportato – come più avanti si vedrà – una notevole fluidità nella definizione delle strutture e dei contenuti, con un percorso evolutivo che ha richiesto un continuo rimaneggiamento degli elementi inizialmente concepiti.
In questo senso, il vantaggio di conservare tutte le informazioni selezionate in etichette XML, capaci di memorizzare ogni dato e assegnargli una precisa posizione nella struttura dei documenti del cartulario, ma al contempo di espandersi, permettendo l’introduzione di numerosi attributi, ha rappresentato la chiave di volta di un progetto la cui vocazione è stata, sin dall’inizio, la volontà di rinnovarsi anche profondamente senza che questa scelta comportasse necessariamente la perdita degli obiettivi iniziali della ricerca in atto.
![]()