|
Creazione automatica di liste ed indici

Per indicizzazione concettuale, o indicizzazione semantica, si intende la rappresentazione del contenuto complessivo o dei contenuti particolari di un documento mediante una o più espressioni sintetiche, verbali o simboliche, che possano costituire di per sé, o unitamente ad altre analoghe espressioni rappresentative del contenuto di altri documenti, un elenco ordinato e consultabile.
Se l’indice è assimilabile ad un codice, attraverso il quale rappresentare e trasmettere il contenuto informazionale del documento allo scopo di renderne possibile il recupero, il linguaggio di indicizzazione è lo strumento per la rappresentazione coerente, formalizzata e sintetica del contenuto concettuale dei documenti, funzionale alla segnalazione e al reperimento degli stessi: un insieme di termini semantici descrittivi e un insieme di regole sintattiche che stabiliscono l’ordine e le modalità di citazione dei termini.
Per una definizione esaustiva si vedano gli standard ISO 5127/5 (Documentazione e informazione - Vocabolario - Acquisizione, identificazione e analisi di documenti e dati, 1981): «l’indicizzazione è l’azione mirante a rappresentare i risultati dell’analisi di un documento con gli elementi di un linguaggio naturale o di un linguaggio documentario, generalmente per facilitarne il reperimento», e ISO 5963 (Metodi per l'analisi dei documenti, 1985): «l’indicizzazione è l’azione di descrivere o identificare un documento nei termini del suo contenuto concettuale». |
Scopo generale dell’indicizzazione è quello di agevolare l’individuazione dei singoli documenti o delle parti di un documento che corrispondano ad una specifica esigenza conoscitiva: in questo senso, nelle sue diverse forme, l’indicizzazione è la principale tra le tecniche di rappresentazione del contenuto concettuale dei testi e in quanto tale, è stata al centro della pratica filologica sin dalla tarda età medievale, epoca a cui va datata l’introduzione massiccia di note, glosse, sommari generali, tematici e alfabetici per l’accesso a punti o soggetti particolari dei manoscritti.

 |
Sebbene una pratica autorevole nella catalogazione e nella soggettazione dei testi si sia pienamente sviluppata sin dal XVI secolo quando, con la larga diffusione del libro a stampa, la nascente filologia ha avvertito l’impellente bisogno di esaminare e conoscere nel dettaglio ogni testimonianza della tradizione testuale, una fondazione scientifica della disciplina si è avuta soltanto agli inizi del Novecento con le riflessioni di Paul Otlet, noto per aver ideato – tra le altre – anche la Classificazione Decimale Universale. |
L’archivio bibliografico implementato per anni dal padre della scienza documentaria è stato basato sul monographic principle, secondo il quale occorre registrare analiticamente ogni documento o parte di documento dedicata a un determinato argomento: nelle parole dello stesso Otlet, il lavoro dell’indicizzatore deve essere mirato non solo al livello dell’intera opera, di un suo capitolo o di una sua sezione, ma anche di ogni dato o “fatto” che sia possibile estrarre dal testo.
Le numerose definizioni di indici e indicizzazione, succedutesi nel tempo, si sono basate sull’unità fisica del documento cartaceo, che ha storicamente costituito il supporto indispensabile – e vincolante – per la registrazione, la conservazione e il recupero dei dati, ovvero per l’attribuzione ad un testo di una rappresentazione contratta, più o meno strutturata, in grado di consentire un’esplorazione selettiva del documento stesso.
Nella forma consueta della carta stampata, indici e concordanze sono strumenti tradizionali del lavoro storico e filologico: alla fine di ogni libro o di ogni repertorio ci si aspetta, di solito, di trovare un indice in grado di rispondere in modo adeguato alle esigenze di chi classifica e inventaria il materiale.
L’indice è un contenitore, una scatola fornita di etichette in cui l’utente è in grado di ritrovare ciò che vi è stato conservato.

Tuttavia, ragionando nei termini della smaterializzazione e dell’aumento informativo proprii dell’ambiente informatico, ci si accorge immediatamente come i legami proposti da un indice tradizionale, pur bene organizzato, siano quanto mai rigidi e vincolanti, consentendo solo un limitato gioco di rimandi.
La reale esigenza delineata dalla consultazione di un archivio elettronico è invece avere a disposizione una rete che permetta di ricavare, mediante termini veramente descrittori, informazioni pertinenti l’oggetto di interesse e l’obiettivo delle domande: da qui, la necessità di disporre di procedure attraverso le quali ottenere per via algoritmica un risultato paragonabile a quello che otterrebbe un indicizzatore esperto nella valutazione dei documenti.
In questo senso l’informatica, enfatizzando vecchi problemi, è in grado di creare una nuova prospettiva nella quale sia possibile costruire una rete navigabile che fuoriesca dalla rigidità di una classificazione calata dall’alto sul mondo dell’informazione testuale per entrare, invece, nella particolarità della terminologia e del lessico, assumendoli come chiavi di ricerca.
Per riuscirci, è però necessario partire dal basso riprogettando, dal punto di vista in cui proietta l’incontro con le nuove tecnologie, la strutturazione dei descrittori pertinenti, capaci cioè di connettersi tra loro attraverso regole e legami che formino una rete concettuale, in modo da consentire una navigazione a qualsiasi profondità e quindi, garantire una maggiore adeguatezza della risposta alla domanda informativa.
I due macrocontesti in cui si è sviluppato il problema dell’indicizzazione su supporto digitale sono stati quello delle collezioni omogenee di corpora testuali – in cui rientra a pieno titolo anche il presente lavoro – e quello delle collezioni eterogenee a crescita imprevedibile, ovvero il corpus complessivo di tutto ciò che è disponibile in Internet, o quantomeno tendenzialmente tale.
In questo caso l’indicizzazione a diversi gradi di automatizzazione e il retrieval che agiscono all’interno dell’intero World Wide Web pongono, naturalmente, problemi decisamente complessi. I primi strumenti di orientamento sul Web sono state le raccolte di risorse per materia, come gli indici manuali per classi e i subject tree: schemi di classificazione su base disciplinare, mantenuti da un singolo o da un gruppo di persone, ottenuti valutando, aggiornando e strutturando le risorse in rete.
A questa fase “pioneristica” si sono poi affiancati, in un secondo momento, i motori di ricerca generici, in grado di generare automaticamente liste di parole – come Altavista e Lycos – i portali e i metadati derivanti da un’attività di catalogazione manuale, tipicamente da parte dello stesso autore, per pervenire all’attuale affermazione di tecniche sofisticate per la valutazione dei documenti e il ranking delle risposte: l’esempio più noto, e più comunemente usato, è Google, che – attraverso un algoritmo basato sul numero di link al documento – è in grado di misurare l’importanza citazionale di ogni sito internet. |
Una text analysis mediata dal computer, veloce e aperta a infiniti confronti, è stata del resto tra i primi obiettivi promossi – sin dalle origini – dall’utilizzo del mezzo informatico in ambito storico e filologico, soprattutto nel contesto di misurazioni di tipo quantitativo, mentre numerosi sono stati, per le edizioni elettroniche, gli approcci e le tendenze sperimentati in sede di indicizzazione testuale, derivanti più o meno esplicitamente dalle vecchie tecniche di soggettazione, sebbene integrate dal riconoscimento della necessità di costruire una “impalcatura” semantica in grado di superare i problemi solitamente associati al riconoscimento lessicale “esatto”.
Tra le tradizionali tecniche di information retrieval in cui, a un comando dell’utente (search, query), corrisponde la risposta di un insieme di record in grado di soddisfare le condizioni richieste, vanno ovviamente annoverati gli operatori booleani, con l’aiuto dei quali è possibile combinare i tre termini and, or e not, per meglio specificare cosa si sta cercando, limitando le pagine trovate ad un numero accettabile. |
Più recentemente, l’utilizzo degli agenti booleani è stato affiancato da numerose possibilità alternative di esplorazione, rese possibili dai vantaggi insiti nel medium elettronico: lo scorrimento (scanning, browsing) di liste alfabetiche lineari di intestazioni corrispondenti a un determinato punto di accesso (autori, titoli, soggetti), percorribili avanti e indietro proprio come avviene scorrendo le schede di un catalogo cartaceo, e la navigazione ipertestuale (browsing o navigating), che permette di partire da un singolo elemento della scheda recuperata per svolgere nuove ricerche (di tipo query o più spesso di tipo scan) senza dover ritornare ogni volta alla maschera o al menu iniziale.
Questi metodi tuttavia, non eliminano le inefficienze maggiori della navigazione in un sito internet che restano, in ogni caso, la difficoltà di trovare quel che si cerca, e solo quel che si cerca, e di trovarlo in tempi ragionevolmente brevi.
L’esigenza è ancora più forte nel caso dell’edizione digitale di un insieme di documenti, dove il semplice apporto di un motore di ricerca, in grado di indicizzare più o meno automaticamente i testi presenti compiendo ricerche sulle parole chiave, non sembra sufficiente ad evidenziare la semantica profonda e il reale contenuto della documentazione storica, essendo l’efficacia dell’informazione recuperata direttamente proporzionale alla precisione della parola chiave impiegata.
Com’è stato giustamente osservato,
l’edizione dei documenti e la loro indicizzazione non sono disgiungibili: si legano, invece, intimamente. Non è affatto paradossale né provocatorio affermare che il lavoro di indicizzazione sia un momento costitutivo della ricerca: e lo sia per molte ragioni,
G. Merlo, Gli indici delle edizioni documentarie, in Resoconto della tavola rotonda sugli indici delle edizioni documentarie: un problema sempre aperto, a cura di P. Pimpinelli, in Bollettino della Deputazione di Storia Patria per l’Umbria, 90 (1993), pp. 191-223:198. |
La principale controindicazione di simili tecniche è dovuta alla povertà semantica delle parole, all’alto tasso di sinonimia e omografia presente nella documentazione – soprattutto in quella medievale – che si traducono in un impatto negativo sulla precisione e il richiamo del sistema di indicizzazione.
L’information retrieval applicata ai documenti medievali, a differenza delle basi dati, si basa infatti generalmente su richieste molto vaghe e che generano – naturalmente – risposte ambigue.
In ambito biblioteconomico e informatico, l’information retrieval è un insieme di tecniche per il reperimento dei documenti rilevanti rispetto ad una determinata esigenza informativa dell’utente, basato su tre criteri di valutazione: rilevanza, richiamo e precisione. Il grado di richiamo (GR) indica il numero di documenti rilevanti recuperati rispetto al numero totale dei documenti presenti; il grado di precisione (GP) è relativo al numero di documenti rilevanti rispetto al numero di documenti recuperati; il rumore indica i documenti non rilevanti recuperati.
Sull’argomento v. l’ormai datato ma assolutamente valido articolo di H.P. Luhn, The automatic creation of literature abstract, in IBM Journal (aprile 1958) Più recenti le pubblicazioni di
|
In questo caso, le soluzioni offerte dai text retrieval classici si scontrano con le necessità degli storici, per cui il testo semplice non risulta più sufficiente ma deve essere integrato con informazioni aggiuntive di diverso tipo: l’esigenza di identificare dei rimandi fra i testi o quella di categorizzarne porzioni distinte sono solo alcuni degli esempi di come il testo lineare sia un formato riduttivo, che si richiede con forza di poter superare.
Anche i numerosi programmi di text retrieval esistenti in commercio,non specificamente orientati al lavoro filologico-testuale, risultano di scarsa utilità perché inadatti a gestire in modo preciso e scientificamente corretto l’indicazione del luogo in cui la forma ricercata ricorre.
Ultima ma non meno importante, l’esigenza di leggere i testi in relazione a informazioni diverse da quelle puramente linguistiche: si pensi come esempio alla necessità di identificare una suddivisione tipografica, tipologica, quando non contenutistica dei testi stessi.
Il computer, è bene ricordarlo, opera su numeri ed elabora codici binari, non significati.

Le parole non gli dicono nulla; gli spazi bianchi e la punteggiatura, che per il lettore sono la naturale scansione del senso del testo, per il computer non sono nulla.
La difficile scommessa, nell’analisi del testimone manoscritto, sta quindi nell’usare lo strumento informatico senza dimenticare che esso è di per sé insufficiente ad esaurire il significato e lo scopo della ricerca.
In questo senso, ancora una volta la codifica delle informazioni contenute nel liber, finalizzata ad indicare in modo utilizzabile dai programmi la struttura soggiacente al testo, è statala scelta più valida per rappresentare la loro notevole irregolarità.
Se già il riconoscimento semantico, con relativo markup, risolve a monte non poche ambiguità, la selezione fra le unità di analisi significative, tipiche o caratteristiche dei contenuti di un documento attraverso l’inserimento di metadati funzionali rappresenta – anche nel caso dell’indicizzazione automatica – la soluzione ideale per l’implementazione e la successiva formulazione di query efficaci, soprattutto nel caso in cui l’utente voglia individuare con esattezza i concetti da ricercare.
Ma per comprendere a pieno la funzionalità della marcatura utilizzata in termini di information retrieval è opportuno fornire un esempio, tratto da un documento contenuto nel cartulario:
quod est subtus <TOP nm="Cribellum, aqua" id="Sorgente del Gabriele" ub="Monte Caputo, Via Riserva Reale, Comune di Palermo, Pa" tipo="el geografico" subtipo="sorgente”>aquam Cribelli</TOP>, cum omnibus iusticiis et pertinenciis suis, eidem monasterio concedimus et donamus … |
Se uno studioso fosse interessato a trovare, nel segmento testuale proposto, l’unità terminologica “Sorgente del Gabriele”, un motore di ricerca tradizionale non sarebbe in grado di restituire alcun risultato, perché prenderebbe in considerazione unicamente la parte testuale non marcata, nella sua sequenza di parole adiacenti, dove l’espressione ricercata non compare in quanto riferita ad un piano semantico diverso, aggiunto dal codificatore nella fase della marcatura.
Con un motore di ricerca tradizionale cioè, lo studioso potrebbe ricercare esclusivamente il termine latino “aquam Cribelli”, come trascritto effettivamente dal testo originale, mentre non potrebbe risalire a questo termine in nessun modo alternativo né tantomeno compiere ricerche incrociate, attraverso una formulazione di interrogazione relativa, ad esempio, all’ubicazione o alla tipologia del toponimo.
L’immissione della codifica e le operazioni che attraverso il linguaggio XML si compiono dunque, materializzano le strutture implicite di un testo, esattamente come – in termini biblioteconomici – la soggettazione di un testo ha il compito di rendere conto di tutti gli argomenti, anche quelli non esplicitamente segnalati dall’autore, che quel testo tratta.
In questo modo, gli automatismi propri delle fasi di conversione automatica effettuate dai tradizionali programmi di text analisys possono essere opportunamente personalizzate per adattarsi alle specifiche esigenze di ogni applicazione.
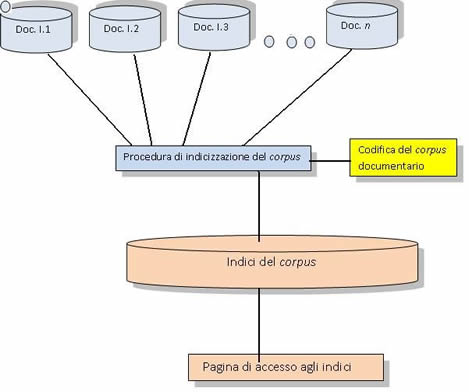
Per facilitare le ricerche sul corpus documentario contenuto nell’edizione digitale del Liber Privilegiorum di Monreale si è inoltre proceduto alla creazione di liste di termini e cose notevoli, che sono state approntate sfruttando le potenzialità dei subset di XML ed in particolare, di uno specifico linguaggio per l’interrogazione, denominato Xpath e finalizzato all’individuazione degli elementi marcati.
La versione 1.0 di XPath è diventata uno standard del W3C nel 1999; per le specifiche si rimanda alla pagina internet |
Una espressione Xpath, che a differenza del vocabolario XML non serve a identificare la struttura di un documento bensì a localizzarne con precisione i nodi, è una stringa contenente nomi di elementi e operatori di navigazione e selezione che specificano al programma i passi da compiere per raggiungere una particolare porzione del documento a partire dall’elemento radice.
Il tipo più comune di espressione XPath è scritta come una sequenza di step per raggiungere un nodo XML partendo dal nodo corrente, il percorso “relativo”; in alternativa, è possibile utilizzare dei percorsi “assoluti” impiegando come riferimento la radice del documento.
Gli elementi tradizionali del codice sono:
. indica il nodo corrente |
Fondamentalmente XPath si compone di espressioni che vengono di volta in volta valutate in un determinato contesto, restituendo uno o più nodi del documento .xml.
In questo modo è stato possibile approntare una procedura per la creazione di liste automatiche, valida per ciascun documento ma operante su tutta la documentazione del liber che, sfruttando la struttura ad alberto dei testi marcati, è stata in grado di estrarre i tag di elemento e gli attributi ad essi associati combinandoli in un numerose varianti.
Nel caso proposto, la trasformazione che ha generato le liste è stata applicata ad un documento .xml unico, nel quale sono stati inseriti i novanta documenti del codice rassachiano, seguendo lo schema sottostante:
<EDIZIONI> |
Avendo precedentemente marcato ogni elemento, è stato quindi possibile attivare una trasformazione che rispettasse la DTD e fosse in grado di restiture liste plurime.
La procedura è infatti in grado di gestire corpora testuali di grandi dimensioni in maniera agevole, costruendo non un unico indice di tutti i documenti del liber bensì, attraverso gli indici creati per ogni singolo documento, una struttura agile e di facile aggiornamento, che garantisca la completa accessibilità e navigabilità all’interno del corpus.
La finalità di una simile operazione è stata ottenere un lessico generale dei termini rilevanti utilizzati come articolazione di indici di accesso alla documentazione e in grado di supportare le esigenze della ricerca.
L’espressione Xpath implementata per l’indicizzazione del cartulario monrealese è costituita da combinazioni di uno o più chunk di testo separati da caratteri speciali e in grado di individuare i contenuti del documento preso in esame o parte di questi, secondo un processo che avviene per passi, detti location step, che messi insieme danno vita ad un percorso completo di localizzazione, ovvero una location path:
<?xml version="1.0" encoding="utf-8"?> |
Analizzando l’esempio, relativo al comando per la creazione di una lista relativa all’elemento <PERSONA>, è possibile innanzitutto notare come la trasformazione presenti in apertura e chiusura delle istruzioni di comando i tag <html> e <body>, indispensabili affinchè il parser riceva l’istruzione di visualizzare il file .xml in formato .html.
Inoltre:
-
La linea di codice <xsl:for-each select="/EDIZIONI/EDITIO"> prende in considerazione ogni tag <EDITIO> contenuto nel nodo genitore <EDIZIONI>: la trasformazione for-each non farà altro che partire dall’inizio del documento e fermarsi appena incontra un tag <EDITIO>, che considererà nella sua interezza, analizzandone tutti i tag figli.
-
La linea di codice QUELLO CHE VUOI <BR/><BR/> non fa altro che scrivere la frase “Quello che vuoi” e andare a capo due volte ogni volta che il for-each trova un tag <EDITIO>.
-
Il value of select restituisce il contenuto del tag specificato tra virgolette, in questo caso il numero del documento.
-
La linea di codice <xsl:for-each select=".//PERSONA"> ricerca all’interno di tutti i documenti il tag <PERSONA>. Il doppio slash permette di prendere in considerazione tutti i tag <PERSONA> all’interno del documento unico; il punto combinato al doppio slash permette di selezionare tutti i tag figli del nodo corrente, estraendoli da ogni singolo documento (<EDITIO>).
-
Il comando <xsl:sort select="@nm"/> permette di visualizzare in ordine crescente l’attributo scelto – in questo caso l’attributo nm (= normalizzazione del nome).
-
<xsl:value-of select="@nm" /> - <xsl:value-of select="@tit" /><BR/>: restituiscono il contenuto dell’attributo nm, diviso da un trattino dal contenuto dell’attributo tit; attraverso questo comando pertanto è possibile selezionare quali attributi di un elemento visualizzare, combinandoli a piacimento. Se ad esempio non interessa visualizzare il nome normalizzato, andrebbe scritto <xsl:value-of select=”.”/>: il punto in questo caso, permette ad XSL di restituire il valore contenuto all’interno del tag, e non i suoi attributi.
Tutta la procedura di indicizzazione è integrata e le modalità operative sono intercambiabili tra di loro.
I risultati finali delle varie operazioni sono confluiti in diversi file .csv (comma separated values, valori separati da virgola), un’estensione di file di solo testo utilizzata per memorizzare dati nei fogli elettronici in cui i dati sono contenuti in campi separati da una virgola e quindi, facilmente trasferibili e convertibili da ogni software, poi convertiti in file .html in grado di esplicitare la trasformazione operata sugli elementi marcati per le persone, i toponimi e le chiese, permettendo l’accesso immediato alla documentazione cui il termine individuato fa riferimento.
Non esiste uno standard formale che definisca il formato CSV, ma alcune prassi più o meno consolidate. In particolare v.
|
I file generati, per ogni elemento, sono due: uno per la trasformazione completa, che comprende il nome normalizzato e tutti gli attributi specificati per l’elemento in questione, e una parziale, nella quale si rende conto esclusivamente del nome normalizzato e della sua identificazione.
L’esito complessivo di queste operazioni non è un indice, ma qualcosa di più elaborato: piuttosto, una guida ragionata ai documenti.
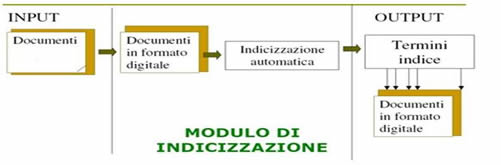
Il modulo di indicizzazione proposto nell’edizione del Liber Privilegiorum on line
È evidente che la possibilità di riordinare dinamicamente i materiali dell’edizione – producendo liste e repertori di dati per qualsiasi elemento marcato in precedenza – potenzia notevolmente il campo d’azione e il controllo dell’universo dei documenti che l’editore, normalmente a fatica, governa.
L’approccio proposto, in qualche modo, migliora la qualità – ma soprattutto la profondità – dell’edizione.
Nel passaggio da un prodotto statico – l’indice su carta – ad uno dinamico, appare inoltre chiaro come la ricerca trapassi sensibilmente dalla finalità documentaria a quella esplorativa, scoprendo caratteristiche del liber che emergono solo attraverso la lettura trasversale proposta dalle liste attivate, nelle quali le unità di senso compiuto e consueto – sintagmi, complementi, proposizioni, periodi – vengono temporaneamente messe da parte per lasciare emergere altre unità di senso, altrimenti non avvertibili.
È questo il modo in cui lo storico, partito dall’idea di usare strumenti informatici per svolgere attività consuete, si trova a poco a poco coinvolto in un nuovo approccio ai testi. Nuovo non concettualmente – le stesse operazioni possono essere compiute con carta e penna, seppure con un enorme dispendio di tempo e di energia – ma operativamente: si risparmia tempo ma, parallelamente, cresce la quantità delle informazioni recuperate e offerte agli studi. Se i tempi del lavoro dello storico o del filologo che usano gli strumenti informatici per svolgere attività consuete non sono più elefantiaci, è possibile stabilire che la tradizione abbia subito – nell’immissione in un contesto tecnologico – una spinta propulsiva, un’accelerazione. Il che non implica, è ovvio, una modifica sostanziale al lavoro di preparazione dei testi.
Lo studio dei testimoni, le scelte a monte, le interpretazioni e le congetture continuano cioè a essere attività fondamentali, per le quali occorre veramente, oltre all’esperienza e alla macchina, la certezza di saper individuare un contesto che restituisca senso: una dote che pare restare essenzialmente umana.